目录
可随意转载Update2022.10.03
一、StyleGAN实战问题
StyleGAN2算法需要非常大的算力,下面是NVIDIA官方统计的训练时长:
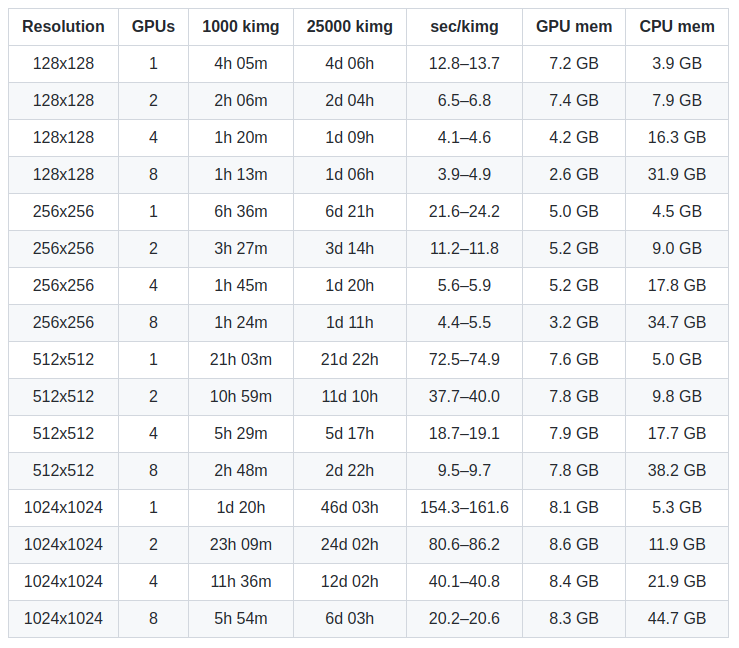
我测试了数据集(256X256)单卡(RTX3090),实际速度比上表还要慢,因此从头训练在商业上是不可行的,需要采用迁移训练(finetune)方式。但是小数据集的迁移训练,StyleGAN2存在过拟合问题。
注:StyleGAN-ada也可以做从头训练。
二、解决方法和步骤
1.下载stylegan2-ada
https://github.com/NVlabs/stylegan2-ada-pytorch为什么用StyleGAN ADA算法呢?
在训练数据量较小(2K)的情况下,StyleGAN2会过拟合,论文中详细论述了这一点。因此做小数据量模型只能用StyleGAN2-ada算法。
不巧的是PaddleGAN没有实现StyleGAN2-ada算法。
另外一个流行的版本(支持ada),附录3的源码解读就是基于这个版本。
2. 处理目标域数据集
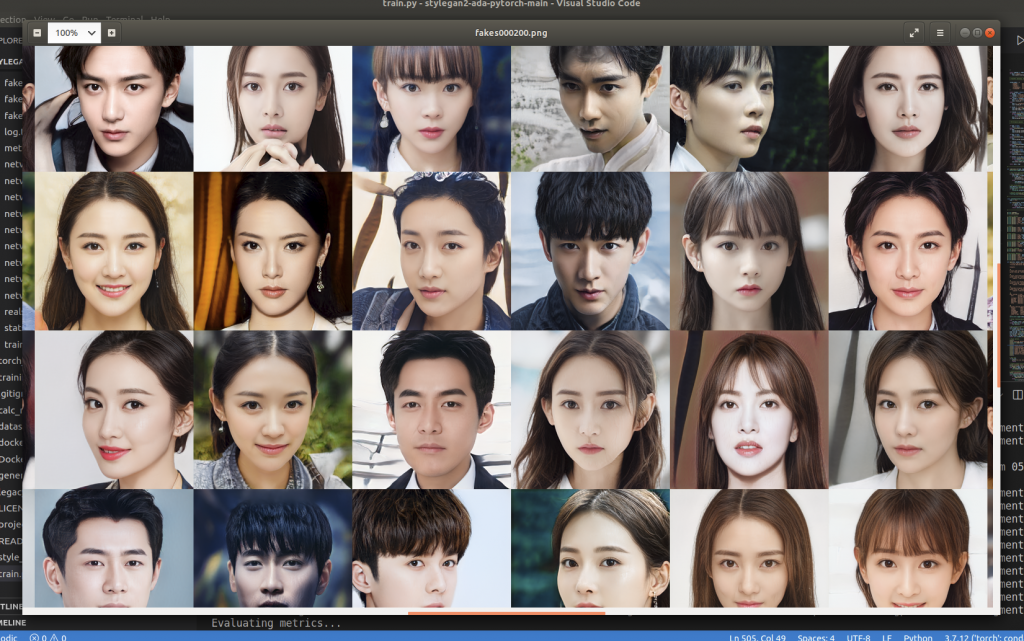
我在网上找到了其他人上传的1024X1024的华人明星脸数据,总共1万张,如下图

我通过以下命令将它们处理成256X256大小的数据:
python dataset_tool.py --source=starface_imagedir --dest=xx/datasets/asian_stars_256_2k.zip --width=256 --height=2563.开始迁移训练
使用下面命令开始迁移训练,注意参数值ffhq256表示从数据集FFHQ的预训练模型(分辨率256X256)中继续训练
python train.py --outdir=output_dir --data=/disk2/Downloads/datasets/asian_stars_256_2k.zip \
--gpus=1 --mirror=1 --resume=ffhq256 --snap=10刚开始迁移训练时的图像:

迁移训练3个小时后的效果:
训练指标日志:
tick 88 kimg 352.0 time 4h 29m 17s sec/tick 125.4 sec/kimg 31.35 maintenance 0.1 cpumem 5.93 gpumem 5.45 augment 0.193
tick 89 kimg 356.0 time 4h 31m 22s sec/tick 124.4 sec/kimg 31.10 maintenance 0.1 cpumem 5.93 gpumem 5.47 augment 0.200
tick 90 kimg 360.0 time 4h 33m 28s sec/tick 125.9 sec/kimg 31.47 maintenance 0.1 cpumem 5.93 gpumem 5.44 augment 0.197
Evaluating metrics...
{"results": {"fid50k_full": 9.033730508841877}, "metric": "fid50k_full", "total_time": 254.87930393218994, "total_time_str": "4m 15s", "num_gpus": 1, "snapshot_pkl": "network-snapshot-000360.pkl", "timestamp": 1657611288.3530803}
...
tick 100 kimg 400.0 time 4h 58m 39s sec/tick 124.0 sec/kimg 31.01 maintenance 0.1 cpumem 5.93 gpumem 5.56 augment 0.205单GPU 400kimg的迁移训练耗时约5小时。
三、更多实战问题
在实战中,我们不可能局限在人物的面部,假如要重建下面的人物呢?

数据预处理
- 使用KolourPaint软件自定义灰色背景图: gray_bg.jpeg
- 下载PaddleSeg预测模型(infer):deeplabv3p_resnet50_os8_humanseg_512x512_100k_with_softmax
- 改造PP-HumanSeg脚本bg_replace.py(保存在百度网盘上)
- 运行如下脚本,批量生成灰色背景图
python bg_batch_replace.py --config deeplabv3p_resnet50_os8_humanseg_512x512_100k_with_softmax/deploy.yaml --bg_img_path /home/ouyang/Downloads/datasets/change_background/gray_bg.jpeg
--img_path /home/ouyang/Downloads/datasets/change_background/nv_zhuang_final_1
--save_dir /home/ouyang/Downloads/datasets/change_background/gray_bg_nv_zhuang_final_1/
四、结论
虽然StyleGAN算法很强大,但是大部分人都只是在官方数据集上玩,没有商业价值。
StyleGAN_ADA算法专门针对小数据集做了代码优化,在迁移学习方面也提供了简单易用的工具,训练时间不再长达数周、数月,它在商业上一定会产生极大的价值。
附录:
附录A:项目python文件解读:
dataset_tool.py
# 请参考上面处理数据集部分generate.py
# 使用自训练模型随机生成一张图片
python generate.py --outdir=outdir --trunc=1 --seeds=85,265,297,849 --network=outdir/00000-gray_nv_zhuang_256_7k-mirror-auto1-resumeffhq256/network-snapshot-001280.pklstyle_mixing.py
# 使用随机生成的两张图做图片融合
python style_mixing.py --outdir=outdir --rows=85,1500 --cols=55,821 --network=outdir/00000-gray_nv_zhuang_256_7k-mirror-auto1-resumeffhq256/network-snapshot-001280.pklprojector.py
在StyleGAN2论文中强调了它的projector跟其他论文(引用[1-10]都不同,比如Image2StyleGAN)。
# 生成指定图片的latent code
# 生成:一段映射过程视频;一个映射文件夹projected_w.npz;一张映射图calc_metrics.py
# 训练过程数据计算,比如FIDlegacy.py
# 把基于tensorflow版本的StyleGAN2和StyleGAN2-ADA模型转换成Pytorch版本。附录B 训练代码(training_loop.py)详解
固定随机种子
torch.manual_seed(random_seed * num_gpus + rank)神经网络加速
torch.backends.cudnn.benchmark = True使用安培架构的TF32类型,但是RTX游戏级显卡不支持
torch.backends.cudnn.allow_tf32 = FalseStyleGAN自定义算子
- conv2d_gradfix
- grid_sample_gradfix
参数cfg_specs
把map改为stylegan2标准的8层
cfg_specs = {
'auto': dict(ref_gpus = -1, kimg = 25000, mb = -1, mbstd = -1, fmaps = -1, lrate = -1, gamma = -1, ema = -1, ramp = 0.05, map = 8),
}参数G_kwargs
{
'class_name': 'training.networks.Generator',
'z_dim': 512,
'w_dim': 512,
'mapping_kwargs': {
'num_layers': 2
},
'synthesis_kwargs': {
'channel_base': 16384,
'channel_max': 512,
'num_fp16_res': 4,
'conv_clamp': 256
}
}图片增广参数
{
'class_name': 'training.augment.AugmentPipe',
'xflip': 1,
'rotate90': 1,
'xint': 1,
'scale': 1,
'rotate': 1,
'aniso': 1,
'xfrac': 1,
'brightness': 1,
'contrast': 1,
'lumaflip': 1,
'hue': 1,
'saturation': 1
}初始化StyleGAN2Loss和Adam优化器
初始化phases
一共四个 Gmain, Greg, Dmain, Dreg,前两个是生成器模块,后两个是判别器模块
导出训练中间结果(组合图)
初始化log
开始训练
phase_real_img: 训练图,尺寸[16, 3, 256, 256]
phase_real_c: one-hot 标签,尺寸[16, 0]