目录
禁止转载,违者必究! Update2024.01.24
导读
Transformer算法从NLP领域进入CV领域后涌现出了一大批精彩的论文,它们被统称为ViT(Vision Transformer)系列算法。
一、ViT算法
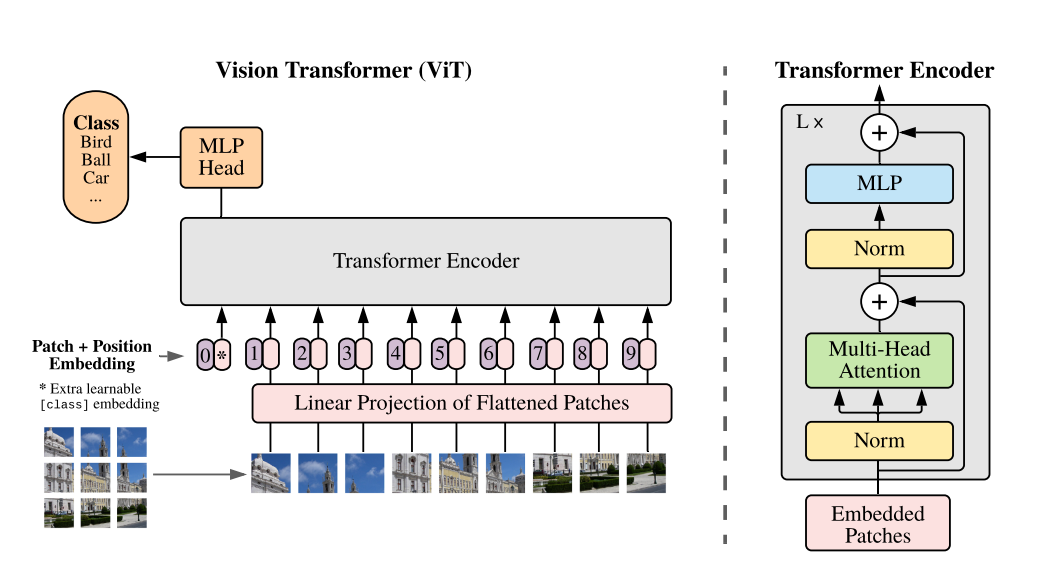
ViT算法来自谷歌2021年的论文《An image is worth 16×16 words: Transformers for image recognition at scale》,ViT算法的思路是:将图片切分后成序列的送入transformer处理,实现了CV和NLP两大领域的大一统。ViT算法打败了传统的CNN算法,实现了在图片分类领域的新SOTA。它的网络架构为Transformer的encoder。
代码地址:大神lucidrains在地址中整理了一大堆ViT的后续开源代码实现。
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)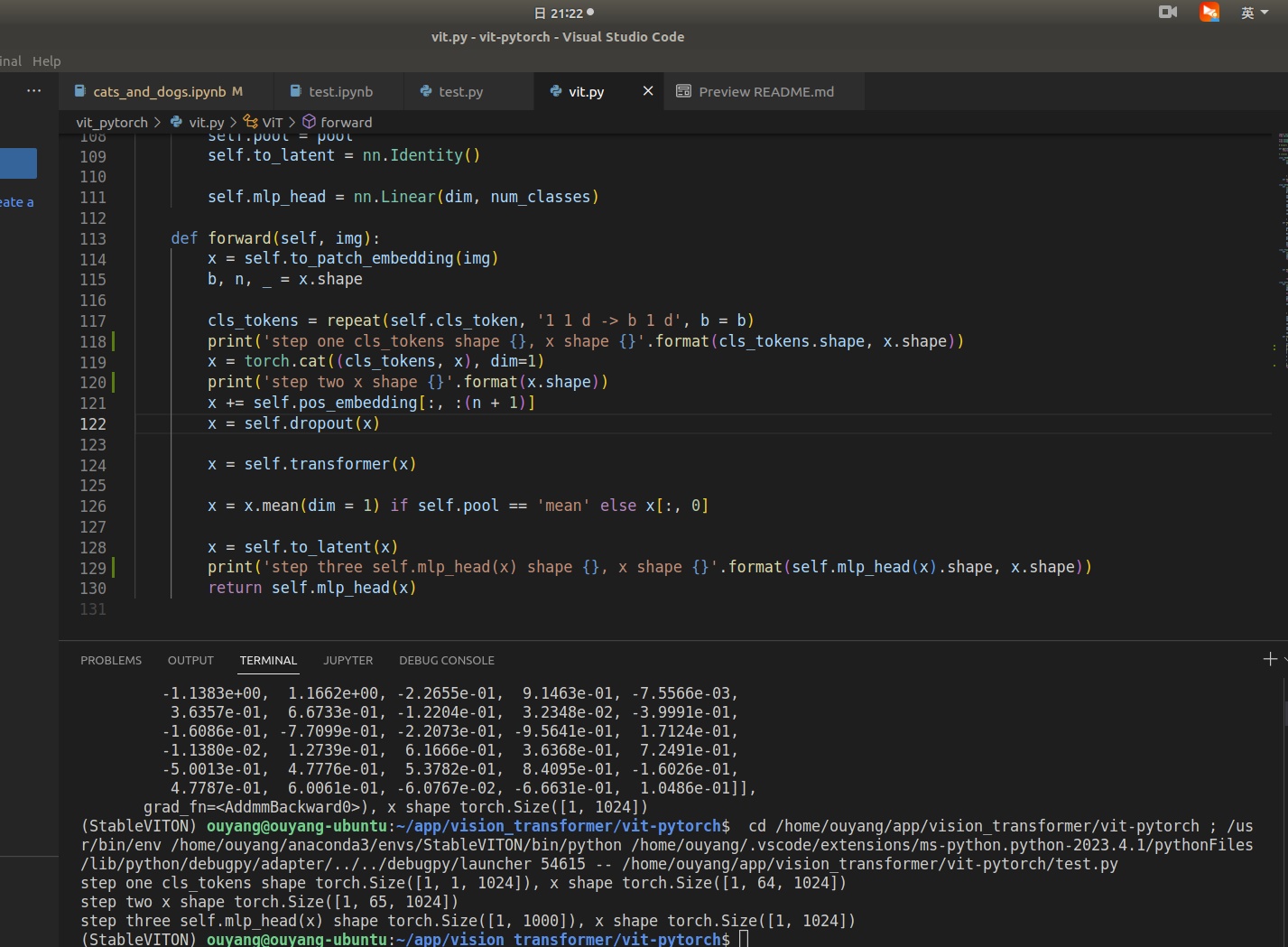
ViT官方github issue说cls_token并没有什么重要,只是为了保持和NLP领域统一。
二、Swin transformer算法
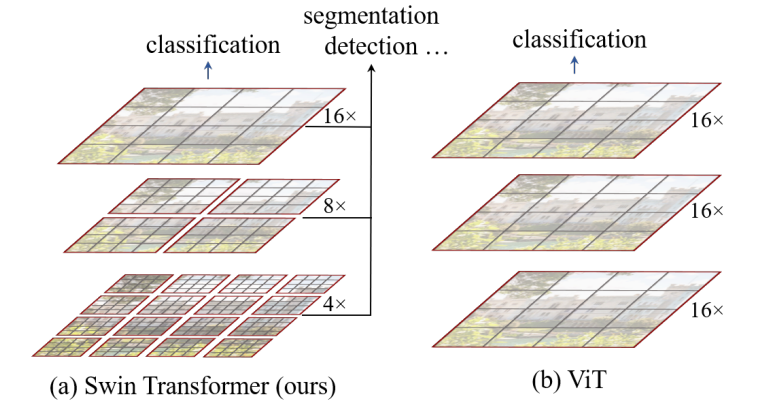
来自微软2021年的论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》,采用了CNN领域常用的FPN,shift window,pool等常用技巧,提升了ViT在多个大小尺度下的效果,不仅可以做图片分类还可以做语义分割和目标检测。
三、MAE算法
来自Facebook的Kaiming大神的论文《Masked Autoencoders Are Scalable Vision Learners》
在NLP领域谷歌的BERT算法可以做句子的完形填空,那么在CV领域这个事怎么做呢?
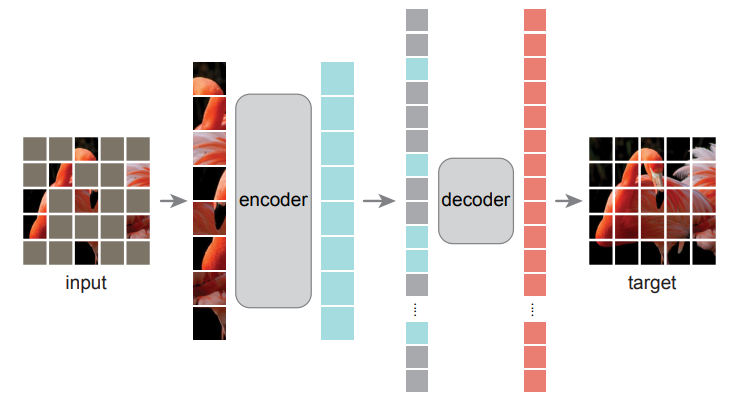
MAE的编码器是一种ViT,在训练期间,大量的图像块(75%)被遮住。编码器被应用于少数可见的图像块。Mask Token在编码器之后被引入,然后由一个小型解码器处理全部的编码图像块和Mask Token重建原始图像。
训练完后,编码器(不需要解码器)被应用于未损坏的图像(完整的图像块集)进行识别任务。
MAE算法可以用来造数据集,并且可以提升类似ViT-Large这种模型能力很强,但缺乏训练数据的算法效果。还可以用在目标检测、实体检测、语义分割等场景并提升它们的算法效果。简而言之,就是能帮别的算法做scale-up.
四、ViTDet算法
以ViT作为主干网络的目标检测算法
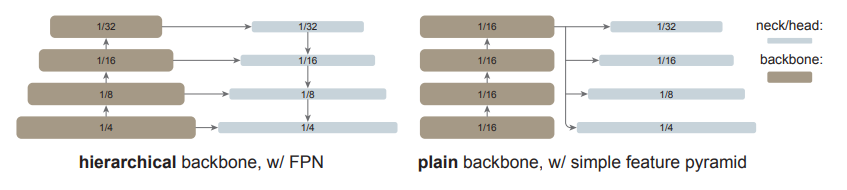
来自Facebook的Kaiming大神的论文 《Exploring Plain Vision Transformer Backbones for Object Detection》。论文中说:大道至简,要发明与下游任务无关的目标检测网络,提出了ViTDet算法。算法从ViT主干网络的最后一层提取feature map,并转换成简单特征金字塔(甚至不需要目标检测中常见的FPN网络)。
HuggingFace Transformers库中也有ViTDet骨干网络的实现。
五、SAM算法

来自Facebook的SAM,支持多种交互形式的的语义分割算法,它包含三个部分
- 图片编码器: 是一个用MAE训练的ViT预训练模型,富含位置知识
- 提示词编码器
- Mask编码器
图片编码器使用ViTDet算法作为backbone(简单修改),image encoder代码在这里。
使用了256张A100训练了3天,SAM完整的预训练模型(主要是image encoder)如下:
背景知识补充
一、基于ViT的视觉语言模型-VLP
来自微软2019年论文《Unified Vision-Language Pre-Training for Image Captioning and VQA》,后逐步升级到ViT。
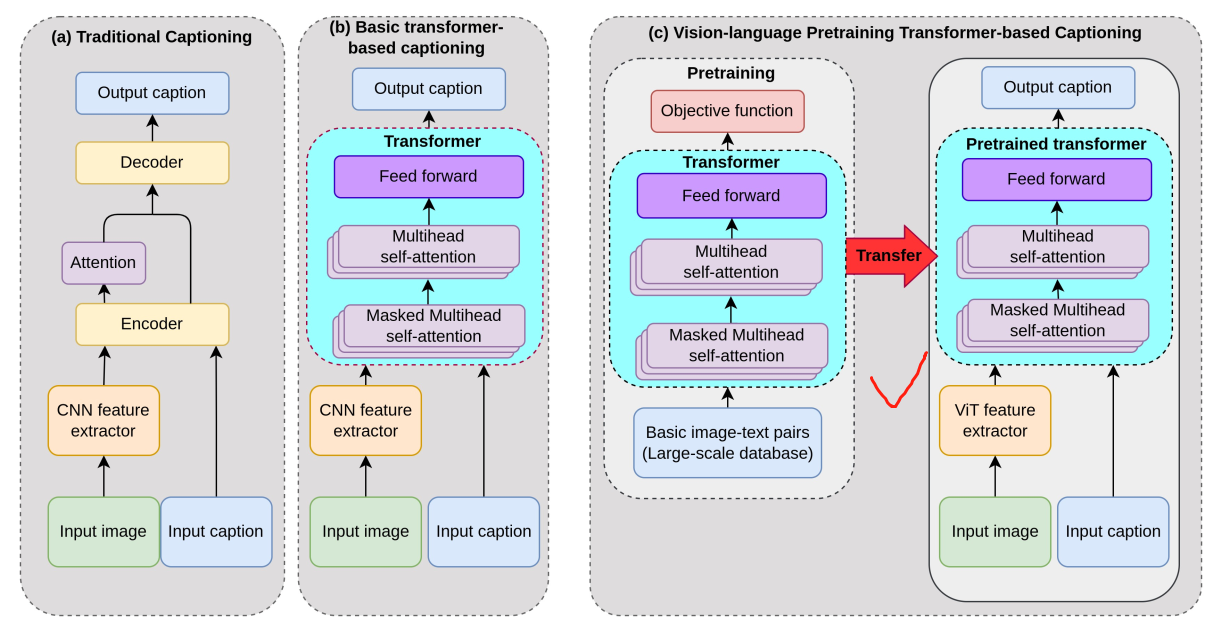
- ViT代替CNN做图像特征提取
- 使用了大型预训练模型
二、CLIP-ViT
来自OpenAI公司的CLIP算法,其中一种是基于ViT的CLIP预训练模型