目录
可随意转载! Update2022.10.11
前言
在之前的文章中,我们学习了DatasetGAN半监督生成语义分割数据集(image+semantic label pair),本文将要介绍的EditGAN利用了DatasetGAN生成的成对数据,通过训练edit vector,在推理时可以利用预训练的edit vector实时编辑(或者在线finetune)编辑目标图片。它的优点是对edit vector解偶能力,可高精度编辑图片。
论文标题:《EditGAN: High-Precision Semantic Image Editing》
简介
EditGAN基本方法:把输入图片x用FPNEncoder训练模型嵌入latent空间,作为”edit vector”; 训练一个semantic网络分支,利用联合概率的特性,修改语义图,通过训练好的网络影响RGB图片(达到了编辑图片的效果)。”edit vector”既可以直接用来生成图片,也可以继续finetune(默认30步)以提高编辑精度。
相关工作
学术上GAN图片编辑一般分为以下几种:
- 利用类标签或者像素级语义标签
- 辅助属性分类器
- 在源和第三方图片间混合(mixing)或者插值(interpolating),用第三方图片来控制目标
- 通过找latent code变量或者网络参数
EditGAN采用的是不同于它们的方法,它依赖于源图和对应的语义分割图的联合概率P(x, y); x是源图,y是语义分割图,且它们的latent code相同。
EditGAN的原理
人为修改语义分割yedit后,因为语义分割图和源图共享latent code,那么我们只要训练网络,优化以下参数:
new w+edit = w++δw+edit ,以匹配yedit的变化。
然而网络可学习的参数只有 δ w+≈ δ w+edit,因此在推理的时候完全可以直接用“edit vector”。当然作者也说了自监督优化一下更好(更慢)。所以EditGAN有三种模式:
- 用训练好的”edit vector” 可以直接做训练
- 用训练好的”edit vector” 参数初始化网络,做refine
- 从零开始训练&推理
EditGAN的训练步骤
- 复用StyleGAN2模型
- 训练FPNEncoder模型,把图片z映射到w+
- 利用StyleGAN2模型和FPNEnocer模型把DatasetGAN数据编码到w+空间
- 训练DatasetGAN模型
- 运行web界面,把StyleGAN2模型,FPNEncoder模型,DatasetGAN模型和FPNEncoder编码的w+图片都用起来
预训练数据
- checkpoint/stylegan_pretrain
- checkpoint/encoder_pretrain/training_embedding 包含masks(png文件),一些npy文件
- checkpoint/datasetgan_pretrain 预训练的的语义分类器(decoder,classifier)
总结
这篇论文公式很少,也没有画任何网络结构,主要是在做实验。论文说除了各种实验,最终实验结果花了3500小时的GPU。
代码精读
页面流程run_app.py
代码问题
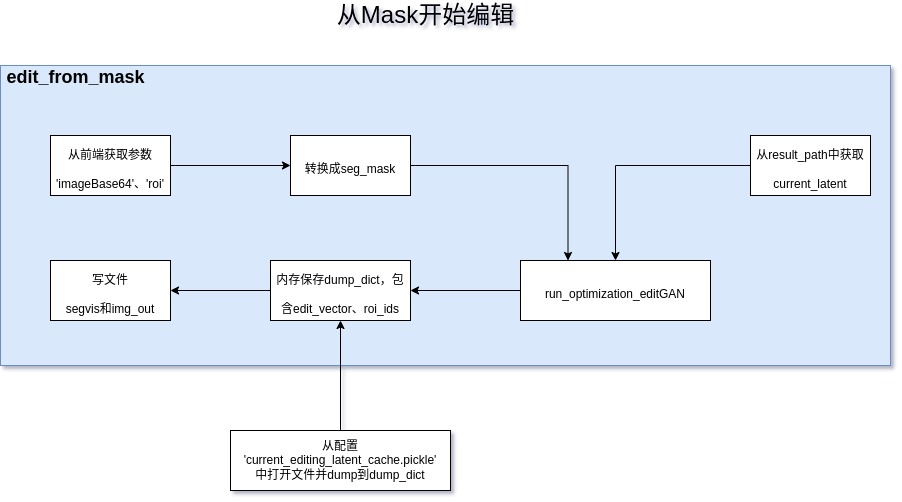
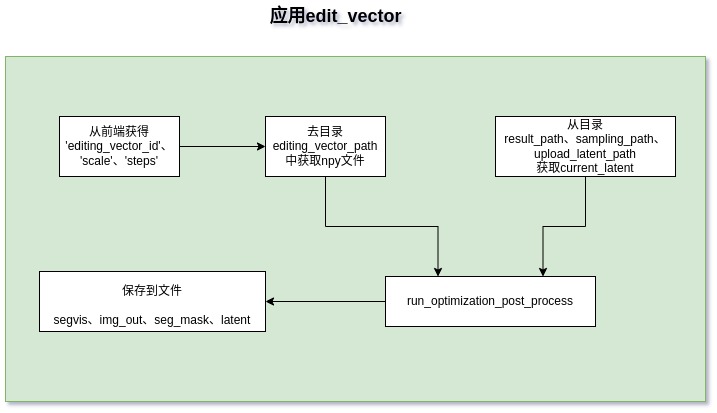
run_optimization_post_process()方法对应页面上finetune下拉框(选择:0次),这是上面介绍的EditGAN的第一种模式。
run_optimization_editGAN() 方法实时做steps=30次优化动作,这是上面论文介绍的EditGAN第二种模式。
这两个方法都会爆显存(3090 24g),论文作者建议去改datasetGAN的输入尺寸(默认1024×1024)和MODEL_NUMBER。
经过定位爆显存的问题是在run_optimization_editGAN()和run_seg()方法,如下:
# 16个affine,拼接的image_features很大,里面存的是Tensor(显存)
# print(image_features.element_size()*image_features.nelement() //1024//1024)
# run_optimization_editGAN 6G;run_seg() 4G
image_features = []
for i in range(len(affine_layers)):
image_features.append(self.bi_upsamplers[i](
affine_layers[i]))
image_features = torch.cat(image_features, 1)
image_features = image_features[:, :, 64:448]
image_features = image_features[0]
image_features = image_features.reshape(self.args['dim'], -1).transpose(1, 0)有三种修改方法:
- 上策:写一个torch.cat 的c++扩展算子,避免内存拷贝
- 中策:按附录的做法,先开一块内存然后直接把Tensor拼接上去
- 下策:每循环一次就做一次gc
a) train_encoder.py代码精读
main方法训练的是FPNEncoder网络(取名叫stylegan_encoder)。
test方法用训练好的FPNEncoder模型,通过embed_one_example()把图片转换到w+空间
FPNEncoder是从SemanticGAN改过来的(DatasetGAN中没有)。
FPN(特征金字塔)是来自目标检测方向论文《Feature pyramid networks for object detection》
b) train_interpreter.py代码精读
训练的是分类器pixel_classifier,就是semantic分支
prepare_data是从DatasetGAN改过来的。它的prepare_model相当与DatasetGAN的prepare_stylegan, 只是因为它支持StyleGAN2和StyleGAN1切换,而DatasetGAN只支持StyleGAN1。
c) EditGAN_tool.py代码精读
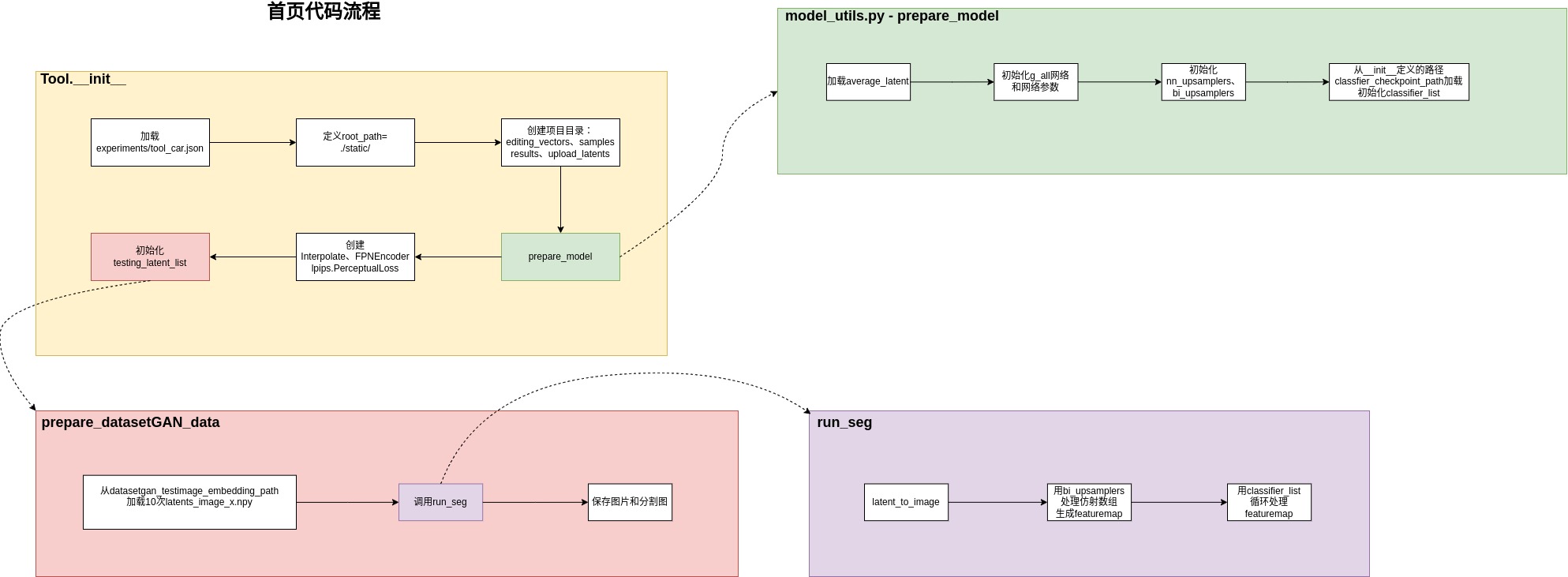
Tool类初始化过程如下:
加载配置文件”experiments/tool_car.json”,读取配置项’encoder_checkpoint’, ‘classfier_checkpoint’;创建四个目录:editing_vector_path,sampling_path,result_path,upload_latent_path。
# 准备模型
self.g_all, self.upsamplers, self.bi_upsamplers, self.classifier_list, self.avg_latent =prepare_model(self.args,classfier_checkpoint,self.args['classifier_iter'],num_class,self.num_classifier)# Interpolate网络(上采样,等同与upsample,pytorch建议用这个api)
self.inter = Interpolate(self.args['im_size'][1], 'bilinear')# FPN网络,这个在DatasetGAN里面还没有
self.stylegan_encoder = FPNEncoder(3, n_latent=self.args['n_latent'], only_last_layer=self.args['use_w'])# 定义lpips损失(人类可视的一种损失函数定义)
self.percept = lpips.PerceptualLoss(model='net-lin', net='vgg', use_gpu=True,
normalize=self.args['normalize']).to(device)附录
torch.cat减少显存拷贝的方法
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
def high_mem():
mylist = []
for i in range(10):
a = torch.zeros(20000,10000).to(device)
mylist.append(a)
print("memory: {}M".format(mylist[0].element_size()*mylist[0].nelement() //1024 //1024 *10))
mylist = torch.cat(mylist, 1)
# del(mylist)
# torch.cuda.empty_cache()
print("memory: {}M".format(mylist.element_size()*mylist.nelement() //1024 //1024))
def low_mem():
x = 20000
y = 10000
mylist = torch.zeros(x*10, y).to(device)
for i in range(10):
start = i * x
end = (i+1) * x
mylist[ start:end, :] = torch.ones(20000,10000).to(device)
print("memory: {}M".format(mylist.element_size()*mylist.nelement() //1024 //1024))
if __name__ == '__main__':
# high_mem()
low_mem()